Windows Azure and Cloud Computing Posts for 5/3/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Access Control, Identity and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Liam Cavanagh (@liamca) explained How to Create an RSS Feed from Windows Azure Table Storage Data on 5/3/2012:
Today I am going to talk about how you can create an RSS feed from Azure Table Storage data. Realistically, you could very easily change this code to create a feed from SQL Azure or any store for that matter (if you get stuck email me at Liam AT Cotega dot com). The code that I am going to use is based on a sample created by DeveloperZen. I am also going to use the trick I blogged about to return the top X rows from Table Storage in reverse chronological order.
The reason I did this is because I needed to be able to provide my customers with an RSS/XML feed of the most recent items logged by the Cotega service. This service logs database statistical information on a users database such as query performance, blocked queries, etc. By providing this data as an RSS feed it is easy for my customers to then embed the feed into their own monitoring systems if they do not wish to use the Cotega dashboard. I am also hoping to use this feed (or another I am creating in JSON) to allow people to build mobile apps so that they can monitor their database from a smartphone. By the way, if you are interested in helping with this, let me know.
How it Works
At the bottom of this post, I have included an MVC3 project that shows how this works. If you open the solution in Visual Studio, you will want to focus on the HomeController.cs file which is located in the /Controllers folder.For this to work, I will use the ServiceModel Syndication namespace for RSS and the Windows Azure namespaces to connect to my storage. As such, I have added the following to the controller.
using System.Xml; using System.ServiceModel.Syndication; using Microsoft.WindowsAzure; using Microsoft.WindowsAzure.StorageClient; using Microsoft.WindowsAzure.ServiceRuntime; using Microsoft.WindowsAzure.Diagnostics;Within this controller there is one key functions and two classes. The first class defines the structure of the data that will be queries from Azure table storage and the second defines an ActionResult for the RSS feed. The Feed function is what gets called when you enter http://x.x.x.x/home/feed in your browser. You may want to set a breakpoint on this when you run the code. Some of the things that this function does is:
- Receive an agentname and username. These parameters are used to filter the results that come back from Azure storage
- Create a connection string to my Windows Azure Table store called storageConnectionString . Notice you will need to replace [ACCOUNTNAME] and [ACCOUNTKEY] with your own credentials.
- Create an EndDt that is set to todays date. I use this as a trick to sort the results in reverse chronological order. For more details on why I do this see this page.
- Take the results of this query and fill up the RSS feed with the 50 most recent items from Table Storage and returns this to the browser
[HttpGet] public ActionResult Feed(string agentName, string userName) { string storageConnectionString = "DefaultEndpointsProtocol=http;AccountName=[ACCOUNTNAME];AccountKey=[ACCOUNTKEY]"; //Select most recent 50 items in desceneding order of date DateTime endDt = DateTime.Now.ToUniversalTime(); //create syndication feed SyndicationFeed feed = new SyndicationFeed("Monitoring Agent Feed", "This is an RSS feed for monitoring agent logged data.", new Uri("http://127.0.0.1:81/alert/feed"), "075211", DateTime.Now); try { // Get the loggged data CloudStorageAccount Account; Account = CloudStorageAccount.Parse(storageConnectionString); // Connect to Azure Tables CloudTableClient TableClient = new CloudTableClient(Account.TableEndpoint.ToString(), Account.Credentials); TableServiceContext tableServiceContext = TableClient.GetDataServiceContext(); // Use rowEndKeyToUse so that I can sort the data in reverse chronological order string rowEndKeyToUse = string.Format("{0:D19}", DateTime.MaxValue.Ticks - endDt.Ticks); var results = (from g in tableServiceContext.CreateQuery("logevent") where g.PartitionKey == userName && g.RowKey.CompareTo(rowEndKeyToUse) > 0 && g.EventType.CompareTo(agentName) == 0 select g).Take(50); //add feed items List syndicationItems = new List(); foreach (LogEvent logEvent in results) { var syndicationItem = new SyndicationItem(String.Format("{0}", logEvent.EventType), String.Format("Watching: {0} Value: {1}", logEvent.Watching, logEvent.EventValue), new Uri("http://cotega.com"), // You may want to replace this guid with the rowkey and partitionkey if not concerned about publishing this in the feed System.Guid.NewGuid().ToString(), logEvent.Timestamp); syndicationItems.Add(syndicationItem); } feed.Items = syndicationItems; } catch (Exception ex) { //Log error } //return feed return new RssActionResult() { Feed = feed }; } } public class LogEvent : TableServiceEntity { public string UserName { get; set; } public string EventType { get; set; } public int EventValue { get; set; } public string Watching { get; set; } public DateTime EventTime { get; set; } } /// /// RssActionResult class. /// public class RssActionResult : ActionResult { public SyndicationFeed Feed { get; set; } public override void ExecuteResult(ControllerContext context) { context.HttpContext.Response.ContentType = "application/rss+xml"; Rss20FeedFormatter rssFormatter = new Rss20FeedFormatter(Feed); using (XmlWriter writer = XmlWriter.Create(context.HttpContext.Response.Output)) { rssFormatter.WriteTo(writer); } } }That’s it. If you have any questions, let me know in the comments.
Download Sample – Azure RSS Feed

![image_thumb1[1]](http://lh5.ggpht.com/-GPgsCGsgJSY/T6RfPIJ8KfI/AAAAAAAAg9E/u7KVNgMiXj4/s1600-h/image_thumb1%25255B1%25255D%25255B6%25255D.png "image_thumb1[1]")
![]()
No significant articles today.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Shaun Xu (@shaunxu) asserted SSDT - Makes SQL Azure Development Easy in a 4/28/2012 post (missed when pubished):
Yesterday I attended an online meeting with Microsoft and got an overview about a new database tool, SQL Server Data Tool (SSDT), which was shipped alone with the SQL Server 2012. After the meeting I decided to have a deeper try and found that it could make our live easier especially for SQL Azure development and deployment.
Install the SSDT
SSDT is part of the SQL Server 2012. It can be installed with the SQL Server 2012 installation. And if you don’t need the whole bunch of SQL Server you can install it through the Web PI or Visual Studio.
SSDT is an integrated environment for database developers to carry out all their database design work for any SQL Server platform (both on and off premise) within Visual Studio. We can use the SQL Server Object Explorer in VS to easily create or edit database objects and data, or execute queries. So the SSDT is not a database engine or runtime, it is just a database tool with some cool feature we can use during our development phase. So you can use SSDT with any existing database tools, such as the SQL Server Management Studio (SSMS) side by side.
Once you have installed the SSDT there will be a new window in the Visual Studio named SQL Server Object Explorer.
The new SQL Server Object Explorer is NOT the Server Explorer which exists in Visual Studio already. Although we can add and view the database connection through the Server Explorer it’s totally different to the new SQL Server Object Explorer.
SSDT highly integrated with Visual Studio. This means we don’t need to navigate to another application to tweak the database when coding and debugging. Also, once the SSDT had been installed there will be a new project type in Visual Studio named SQL Server Database project, which we will use later.
This project type is different than the original database project in Visual Studio Database Edition. It has another project extension name and has different functionality.
Statement Oriented, Instead of Command Oriented
SSDT adopts a totally different concept to maintain and control your database. It’s statement oriented, instead of command oriented. This means, by using SSDT you only need to care what your database schema should be. And you will never care about how to update the database to this schema. You will use T-SQL as a statement language to define the tables, views, keys, indexes, etc. you want and just save those CREATE scripts in SSDT project, and then SSDT will help you to apply the changes to the database.
For example, currently we have a database with a table and a view associated.
1: CREATE TABLE [dbo].[Table1] (2: [Id] INT NOT NULL,3: [Name] NVARCHAR (50) NOT NULL,4: PRIMARY KEY CLUSTERED ([Id] ASC)5: );6:7: CREATE VIEW [dbo].[View]8: AS SELECT * FROM [Table1]In traditional way, if I want to extend the size of the Name column, I need to write an ALTER TABLE statement and then refresh the view. These scripts is focusing on how to change the database to the schema I want, but it cannot give me a very clear information on what schema I want it to be. This script is command oriented.
In SSDT we don’t need to care about how to alter the table and refresh the view. I only need to change my database creation script, which means just changed the CREATE TABLE script which have the length from 50 to 100 of the Name column. And then SSDT will compare my current script and the existing database schema, generate the upgrade script and run it.
SSDT also includes some other features such as the target platform validation, which means you can check your script against a database platform like SQL Server 2008, 2012 and SQL Azure, make sure it works before you run it.
It also provides the local database feature. By using this feature you can download a database schema copy from the production or center database and use it only by yourself when developing and testing. You can change the schema of your local database. All changes will be in some script files with many CREATE statement, you don’t need to write the alter script at all. And if you think it’s OK, you can use SSDT to update your changes back to the center database. SSDT will help you to alter the database to your latest schema. This is very useful when a team is working on the same database, and very useful when you are working with SQL Azure. Since frequently connect with the SQL Azure and upload download data is NOT free. In the following part I will demonstrate how to use SSDT to develop and upgrade the SQL Azure database.
Create SQL Azure Database and Schema in SSDT
SSDT can integrated with the SQL Azure very well. Just open the Visual Studio and the SQL Server Object Explorer window, right click on the root node and click the Add SQL Server item.
Specify the SQL Azure connection information in the popping up window.
Then it will appear in the SQL Server Object Explorer. You can create a new SQL Azure database in this window directly. Just expand this server and database node then right click to select the Add New Database. Then type the name of database. After several seconds the database will be created on your SQL Azure.
SSDT will create a 1GB Web edition SQL Azure database. If you want to create a database in different configuration you need to write the CREATE DATABASE command manually, or through the development portal.
Expand this new database you can see the tables, views, programmability, etc. in the list. Now let’s create a new table. Right click the Tables node and select Add New Table.
As you can see the table designer appeared! If you had been working with SQL Azure a bit while you should know that till now there’s no table designer in the local SSMS. And the only one designer is by using the web-based SQL Azure database manager, originally named “Project Houston”. But in SSDT you can use the designer to create and alter your tables. And more cool stuff is, when you change the table schema either in the designer or in the script panel they will be synchronized and refreshed automatically. Let’s added two columns through the designer and rename the table name in the script panel.
Then we can click the Update button at the top of the designer to apply the changes to the database. In this case, it will be run on the SQL Azure.
The SSDT will compare the schema between the SQL Azure database and our script, to generate the update script for us. In this case since the SQL Azure database is empty it will tell us just create a new table. But if our changes were huge SSDT will generate more steps to upgrade the schema.
We can retrieve the update script by clicking the Generate Script button, and we can ask SSDT to execute the script for us. Let’s click the Update Database button to apply the changes. Once the SSDT is performing the script steps will be shown in the Data Tool Operations window in Visual Studio. And you can see my script was executed finished successfully.
Back to the SQL Server Object Explorer window the new table had been shown there. And we can view its data, by using the context menu the View Data item, even though at this moment there is no data available.
Database Project and Local Database with SQL Azure
Assuming I’m a developer who is going to work with the database I had just created. Let’s have a look on how to use the SSDT database project and local database feature to make it easier and effectively.
There are many reasons that it is not a good approach to develop against the SQL Azure database directly. The first one is the cost. Since all transaction and data our bound is billed, I don’t want to frequently connect to the SQL Azure in development and test phase. The second reason is the performance. Connecting to the SQL Azure will be more slower than connecting to a local database of course. My boss doesn’t want me to waste of time on waiting for the SQL Azure response. The third one is, if I have some colleagues who are working on the same SQL Azure database, we might be affect each other by changing the schema and add or remove some data. So what I want is to download the SQL Azure database to my local machine, update the schema and data based on my business needs, develop and test, then finally update my changes of the database back to SQL Azure and my code to TFS.
To download the SQL Azure database I will create a new SQL Server Database project. And then right click on the project node from the Solution Explorer and select Import, Database.
SSDT allows to import database schema from a Data-tier Application package, a live database or a database creation script.
In the popping up window I selected the database which I had created on SQL Azure and then click Start button.
SSDT will connect to the SQL Azure database, grab the schema information and generate the creation script to me, and added them into the database project.
SSDT will only download the schema from the source database. It will NOT download and data.
In the Solution Explorer there will be some scripts listed under the related folders. In this example since I only have one table so there’s only one script under the table folder. Also in the SQL Server Object Explorer window there’s a new server node added with the name of (localdb)\Database 2 (SQL Server …). This is the local database SSDT created for me.
You can find the local database files (MDF and LDF) in the folder named Sandbox under you database project folder.
But currently there’s no table in the local database. We need to run the database project to let it generate the database content to us. Select the local database node in the SQL Server Object Explorer and click F5. In the output we can see the database had been deployed to the local database and the table was shown as well.
Now the schema of this database is exactly the same as what it is on SQL Azure, and I can develop against it rather than connecting to the SQL Azure. Select the database node we can find the connection string.
I don’t want to demonstrate how to use the local database through C# and ADO.NET. It’s exactly the same as what we are doing with SQL Server every day. I will focus on database part in this post.
Assuming we need a lookup table named Country and a new column in the Product table named CountryID, and a foreign key between them. We can add and modify on our local database. This is very quickly and will not affect other developers who is related with the SQL Azure database. In the Solution Explorer right click on the Tables folder and add a new Table item.
And in the designer added a column named Name and then save it. Now there will be two scripts under the Tables folder.
And then double click on the Product.sql file to open its design window. Let’s append a new column named CountryID and add a new foreign key from the design panel as well.
Input the foreign key name and then we need to manually specify the columns associated with it through the script panel at the bottom.
Finally, to make our change applied to the local database just run (click F5) on the database project. The output window told us the deployment successful and in the SQL Server Object Explorer the new table and key will be shown as well.
Now let’s assum[e] I had finished the development and testing and I want to update my database changes to the SQL Azure. In database project this can be done by right click the project and select Publish. In the publish window I selected the target database connection information and then click the Publish button. SSDT will compare the schema between the SQL Azure database and my local database, generate the update scripts and run.
You can check the “Add profile to project” so that your publish setting can be saved and used in the future. Clicking the “Generate Script” will let the SSDT generate the update script to us without performing it.
After a while the SQL Azure database will be changes based on what we have done on the local database.
Target Platform Validation and Schema Compare
Besides the designer and local database, there are some other features can help us for SQL Azure development. The first one is target platform validation.
As we know, even though the underlying database engine is same between SQL Server and SQL Azure, there are some limitation of SQL Azure. When we create or change the schema of SQL Azure it’s very hard to remember all these limitations and causes a service failure. But now, SSDT provide the target platform validation feature which means it can check our schema definition scripts based on the database platform we specified. To demonstrate this feature let’s create another table named Area and with two columns: ID and Area. But let’s remove the primary key of this table. This kind of table is called “Heap” sometimes, which is supported by SQL Server but not by SQL Azure.
Right click the database project and click Build. This will perform the target platform validation. By default our database project is using SQL Server 2012 as its platform so the Area table is OK. Next, let’s click the Property menu item of the database project and change the target platform to SQL Azure.
Then build again, we will get an error said that in SQL Azure a clustered index is required in a table. So when we using SQL Azure through the SSDT we can let it check the schema for us before publish to the cloud.
Another cool feature is schema compare. In fact when we perform any updates in SSDT it will invoke this feature to generate the update script. But we can invoke it manually by clicking the Schema Compare from the context menu of the database project. Then select the target database we want to compare with our database project. Then it will show the differences by tables, views, etc..
Summary
SQL Server Data Tool (SSDT) is not a new product, but was improved a lot and published alone with the new SQL Server 2012. SSDT resolved the problem that how to define, trace and update the database by introducing the statement oriented script principle. This makes the developers focus on what the database should be instead of how to upgrade the database, by using its powerful compare engine and script generator engine.
SSDT also provides the local database and database project feature as well. Working with the script update engine we can easily download the database to the development local and amend. This will not affect the center database. And the developer can publish his/her changes back to the center database very easily. And this is much more useful when working with SQL Azure.
SSDT also make it possible to trace the history of database changes in source control service, such as TFS, by checking the scripts in the repository. Since it only contains the schema definition it would be very easy to find who, when and what to changes to the schema.































<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Peter Horsman reported Updates to Windows Azure Marketplace Offer More Flexibility and Opportunity on 5/4/2012:
Recent updates to the Windows Azure Marketplace promise to make things a little bit easier for publishers, developers and their customers.
First, we’ve introduced promotion codes! Publishers can now create special discounted offers for their customers with promotion codes. These custom codes can be included in targeted campaigns or on flyers or giveaways for special events. Customers simply type the code into the publisher portal to take advantage of their special offers.
Publishers should contact Microsoft at datamarketbd@microsft.com to set up promotion code self-service on their offers.
Next, the Windows Azure Marketplace now offers Data Cleansing APIs for developers: 12 offers from 6 providers. For more details, explore our Data Quality Services category here.
Finally, we’re excited to announce that the Marketplace now also supports the Dutch language.
Today’s announcements are part of our ongoing commitment to provide a trusted, easy to use Marketplace for publishers, developers and data consumers worldwide.
For more information on these and other benefits, visit the Windows Azure Marketplace today.
I’m having problems uploading 500,000-row datasets to the Marketplace DataMarket, as reported in my Microsoft Codename “Data Transfer” and “Data Hub” Previews Don’t Appear Ready for BigData post updated 5/4/2012.
<Return to section navigation list>
Windows Azure Service Bus, Access Control, Identity and Workflow
Richard Seroter (@rseroter) asked Windows Azure Service Bus EAI Doesn’t Support Multicast Messaging. Should It? on 5/4/2012:
Lately, I’ve been playing around a lot with the Windows Azure Service Bus EAI components (currently in CTP). During my upcoming Australia trip (register now!) I’m going to be walking through a series of use cases for this technology.
Super cool! However, the key word in the previous sentence was “or.” I cannot send a message to ALL those endpoints because currently, the Service Bus EAI engine doesn’t support the multi-cast scenario. You can only route a message to a single destination. So the flow above is valid, IF I have routing rules (e.g. “OrderAmount > 100”) that help the engine decide which of the endpoints to send the message to. I asked about this in the product forums, and had that (non) capability confirmed. If you need to do multi-cast messaging, then the suggestion is to use Service Bus Topics as an endpoint. Service Bus Topics (unlike Service Bus Queues) support multiple subscribers who can all receive a copy of a message. The end result would be this:
However, for me, one of the great things about the Bridges is the ability to use Mapping to transform message (format/content) before it goes to an endpoint. In the image below, note that I have a Transform that takes the initial “Order” message and transforms it to the format expected by my SQL Server database endpoint (from my first diagram).
If I had to use Topics to send messages to a database and web service (via the second diagram), then I’d have to push the transformation responsibility down to the application that polls the Topic and communicates with the database or service. I’d also lose the ability to send directly to my endpoint and would require a Service Bus Topic to act as an intermediary. That may work for some scenarios, but I’d love the option to use all the nice destination options (instead of JUST Topics), perform the mapping in the EAI Bridges, and multi-cast to all the endpoints.
What do you think? Should the Azure Service Bus EAI support multi-cast messaging, or do you think that scenario is unusual for you?




After reading Richard’s article I’d vote for Service Bus to handle multicast messaging.
Clemens Vasters (@clemensv) described NHTTP and the Windows Azure Service Bus on 5/3/2012:
I’m toying around with very small and very constrained embedded devices right now. When you make millions of a small thing, every byte in code footprint and any processing cycle you can save saves real money. An XML parser is a big chunk of code. So is a JSON parser. Every HTTP stack already has a key/value pair parser for headers. We can use that.
All rules of RFC2616 apply, except for section 7.2, meaning there is must never an entity body on any request or reply. Instead we rely entirely on section 7.1 and its extensibility rule:
- The extension-header mechanism allows additional entity-header fields to be defined without changing the protocol, but these fields cannot be assumed to be recognizable by the recipient. Unrecognized header fields SHOULD be ignored by the recipient and MUST be forwarded by transparent proxies.
All property payloads are expressed as key/value pairs that are directly mapped onto HTTP headers. No value can exceed 2KB in size and you can’t have more than 32 values per message so that we stay comfortably within common HTTP infrastructure quotas. To avoid collisions with existing headers and to allow for easy enumeration, each property key is prefixed with “P-“
POST /foo HTTP/1.1
Host: example.com
Content-Length: 0
P-Name: “Clemens”HTTP/1.1 200 OK
Content-Length: 0
P-Greeting: “Hello, Clemens”(The fun bit is that the Windows Azure Service Bus HTTP API for sending and receiving messages already supports this exact model since we map custom message properties to headers and the HTTP entity body to the body of broker messages and those can be empty)

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Nathan Totten (@ntotten) and Nick Harris (@cloudnick) produced CloudCover Episode 79 - Adding Push Notifications to Windows 8 and Windows Phone apps using Windows Azure on 5/4/2012:
Join Nate and Nick each week as they cover Windows Azure. You can follow and interact with the show at @CloudCoverShow.
In this episode, our very own Nick Harris —Technical Evangelist for Windows Azure and all round good guy — builds on the foundational knowledge presented in Cloud Cover Episode 73 and takes us on a deeper dive into how add Push Notifications to both Windows 8 and Windows Phone applications using MPNS, WNS, Windows Azure and a number of re-usable NuGet packages. The session is code heavy so enjoy!
In the News:
- Announcing Native Windows Azure Libraries and Special Free Pricing using Twilio for Windows Azure Customers
- Automatic Migration of Access Control Service Version 1.0
- Announcing Casablanca, a Native Library to Access the Cloud From C++

Joel Forman reported on Recent Windows Azure Project Highlights: Media, Ws-fed and More… in a 5/4/2012 post to the Slalom Consulting blog:
I haven’t been blogging as much in the past few months, but I have a good excuse. I have been heads down over the last few months working with several clients on different, innovative projects that leverage the Windows Azure Platform. From media processing to federated authentication to scalable services and database, Slalom Consulting has been doing great work in the cloud.
Project Highlight: Cloud-based Tax Form Application
The web application is configured against the Access Control Service to allow users to authenticate via 2 identity providers. Employees of the firm, who manage their tax clients, authenticate with their corporate credentials via Active Directory Federation Services. Clients themselves authenticate via custom client identities. The client identity store sits behind a custom STS (security token service), also an ASP.NET MVC3 application leveraging Windows Identity Foundation, and running in Windows Azure compute.
Project Highlight: Image and Video Processing in the Cloud
Slalom engaged with a Media and Entertainment company to conduct a pilot around media processing in the cloud. A cloud-based image and video processing solution was developed as part of this engagement. The basic workflow around the solution is as follows:
- The user uploads an asset via a web user interface running in Windows Azure.
- The web site, running as a web role, stores the asset in BLOB storage and writes a message to a Windows Azure Queue indicating the type of transcoding to perform.
- The web site records a job submission to Windows Azure Table Storage for tracking.
- From that point, a series of worker roles poll the transcoding queues for work requests to perform different actions on the asset. There is a worker role for image processing, a worker role for video processing, a worker role for video thumbnail processing, and a worker role for performing encryption tasks.
- Upon completion of the work, the worker roles places the completed asset back into a blob storage account for access and generates a shared access signature which limits access to the final asset.
In addition, an auto-scaling solution was deployed, running in a separate Worker Role using Windows Azure Autoscaling Application Block. This provided the ability to scale up and down the number of worker roles based on the backlog in the queue.
Finally, as part of this engagement, Slalom worked with Microsoft to expose the client to Windows Azure Media Services, Microsoft’s future cloud-based media processing platform. This pilot could easily be ported to leverage Windows Azure Media Services for many of these different media workflow tasks.
Project Highlight: Federated Authentication for a Cloud-hosted Web Application
Slalom engaged with a Fortune 500 company to deliver a cloud-hosted secure web application to an approved set of employees and partners. The application runs in Windows Azure compute as a Web Role and leverages Windows Identity Foundation. Using the supported WS-Federation protocol, end users are required to authenticate with the enterprise’s existing identity management system. This existing on-premise system already managed identities of employees and partners. Through this solution, the company was able to realize the benefits of deploying this solution on Windows Azure, such as cost, time to market, and scalability, while still meeting security requirements.These are just some of the innovating cloud projects Slalom has been delivering so far in 2012. Stay tuned for more highlights throughout the rest of the year!

Krish Ragh described Getting Started with Windows Azure for Java in a 5/3/2012 post:
The Windows Azure SDK for Java provides client libraries and tools to allow Java developers to quickly and easily create applications that run on Windows Azure or leverage Windows Azure services such as Windows Azure Storage or Service Bus.
Downloading and Installing the Windows Azure SDK
To get started with Java on Windows Azure, you need two major components:
- Windows Azure Emulator and Eclipse Tooling
- Windows Azure Client Libraries for Java
You can install the Windows Azure Emulator and Eclipse Tooling directly from Eclipse. You can download the Windows Azure Client Libraries for Java either manually or via Apache Maven. The instructions on how to do this are available here.
In the rest of this blog post, I’ll discuss some key features and supported scenarios of Java in Windows Azure, and highlight additional resources where one can learn further.
Windows Azure Service Runtime with Java
The Windows Azure Service Runtime library provides functionality that allows your application to interact with the Windows Azure environment. It also allows your application to determine information about the roles, role instances, and role environment. Examples of where you would use the Service Runtime include:
- Determining configuration settings, local resources, and role-related information.
- Responding to role environment changes, for example a change to a configuration setting.
- Requesting a recycle of a role instance.
The RoleEnvironment, RoleInstance, and Role classes are the main classes in the Service Runtime. They are described conceptually in greater detail here and described from an API perspective at the Javadocs.
SQL Azure with Java
This topic on SQL Azure and Java describes in great detail the common scenarios that you may wish tackle with SQL Azure and Java. It is helpful to also understand how to use the JDBC driver for SQL Azure and SQL Server, and conceptually overview SQL Azure itself, should you not be fluent in it. Remember that to attempt these scenarios, your environment must meet the following pre-requisites:
- A Java Developer Kit (JDK), v 1.6 or later.
- A Windows Azure subscription
- If you are using Eclipse:
- Eclipse IDE for Java EE Developers, Helios or later
- The Windows Azure Plugin for Eclipse with Java. During installation of this plugin, ensure that Microsoft SQL Server JDBC Driver 3.0 is included
- If you are not using Eclipse:
Understanding and Using the Windows Azure Plugin for Java
The Windows Azure Plugin for Eclipse with Java provides templates and functionality that allow you to easily create, develop, test, and deploy Windows Azure applications using the Eclipse development environment. The Windows Azure Plugin for Eclipse with Java is developed by Persistent Systems Ltd, and is sponsored and designed by Microsoft. It is an Open Source project, whose source code is available under the Apache License 2.0 from the project’s site at http://sourceforge.net/projects/waplugin4ej/.
The following topics provide information about the Windows Azure Plugin for Eclipse with Java.
- What's New in the Windows Azure Plugin for Eclipse with Java
- Installing the Windows Azure Plugin for Eclipse with Java
- Creating a Hello World Application Using the Windows Azure Plugin for Eclipse with Java
- Using the Windows Azure Service Runtime Library in JSP
- Enabling Remote Access in Windows Azure Using Eclipse
- Debugging in Windows Azure Using Eclipse
- Miscellaneous Role Configuration Settings
- Session Affinity
- How to Maintain Session Data with Session Affinity
- Displaying Javadoc content in Eclipse for the Windows Azure Libraries for Java
Tutorials and How-to Guides on Windows Azure + Java
In addition to the resources above that describe how to exploit the Windows Azure plug-in for Eclipse, the following select collection of existing tutorials and how-to guides will also be useful.
On-Premise Application with Blob Storage: This example shows you how you can use Windows Azure storage to store images in Windows Azure. The code is for a console application that uploads an image to Windows Azure, and then creates an HTML file that displays the image in your browser.
How to Use the Blob Storage Service from Java: This guide shows you how to perform common scenarios using the Windows Azure Blob storage service and the Windows Azure SDK for Java. The scenarios covered include uploading, listing, downloading, and deleting blobs.
How to Use the Queue Storage Service from Java: This guide shows you how to perform common scenarios using the Windows Azure Queue storage service and the Windows Azure SDK for Java. The scenarios covered include inserting, peeking, getting, and deleting queue messages, as well as creating and deleting queues.
How to Use the Table Storage Service from Java: This guide will show you how to perform common scenarios using the Windows Azure Table storage service and Windows Azure SDK for Java. The scenarios covered include creating and deleting a table, inserting and querying entities in a table.
How to Send Email Using SendGrid from Java: This guide demonstrates how to perform common programming tasks with the SendGrid email service on Windows Azure and Windows Azure SDK for Java. The scenarios covered include constructing email, sending email, adding attachments, using filters, and updating properties
How to Use Service Bus Queues from Java: This guide shows you how to use Service Bus queues and use the Windows Azure SDK for Java. The scenarios covered include creating queues, sending and receiving messages, and deleting queues.
How to Use Service Bus Topics/Subscriptions from Java:This guide shows you how to use Service Bus topics and subscriptions and use the Windows Azure SDK for Java. The scenarios covered include creating topics and subscriptions, creating subscription filters, sending messages to a topic, receiving messages from a subscription, and deleting topics and subscriptions.

Jim O’Neil (@jimoneil) described Integrating Twilio with @Home with Windows Azure in a 5/3/2012 post:
I started this post about two months ago (right after meeting Jon Gottfried, one of the Twilio evangelists, at Boston Startup Weekend), but it took yesterday’s announcement to light a fire under me and finish it up!
In case you’re not familiar with @Home with Windows Azure, it’s a project my colleagues Brian Hitney, Peter Laudati and I put together that leverages Windows Azure to contribute to Stanford’s Folding@home medical research project. We lead you through deploying a simple Windows Azure application to a free 90-day trial or MSDN account, and in turn your code contributes compute cycles to the Stanford project.
In this post, I’ll cover the steps I took to get up and running with a Twilio trial account and the changes I made to the original @home with Windows Azure code to enable features that
- send an SMS to my cell phone whenever a Folding@home job completes, and
- allow me to send a text message and get an update on the progress of current folding jobs.
Setting up your Twilio account
This is about as effortless as possible. Simply click the Get Started button on Twilio’s signup page, enter your name, e-mail and password, and you’re in. You’ll have a free account at that point, and as mentioned in the announcement yesterday, you’ll get a credit for 1000 texts or inbound minutes when you upgrade from that free account. You don’t need to do the upgrade now though to get a sense of how it all works.
Once your account is set up, you’ll see your dashboard (below), which includes getting started links, analytics, and most importantly your account credentials and sandbox app. The sandbox app gives you a telephone number that you can use to both send and receive text and voice messages for development and testing.
Since you’re using a trial account with a sandbox application there are a few restrictions on usage; these go away when you buy a number and upgrade to a paid account. Specifically,
You must verify numbers that you own in order to send text messages to them. Do this via the Verified Number tab under the Numbers menu. After you enter your number, you’ll see a verification code on the screen and receive a phone call to the number you entered. Answer that call, enter the verification code, and your number will be now able to send and receive messages.
Whenever you send a text message from your phone to your Twilio sandbox application, you'll have to preface that message with the Sandbox PIN you see in your dashboard.
Getting Twilio client libraries
Twilio exposes its SMS and telephony capabilities via REST endpoints and Twilio Markup XML (TwiML), so it follows that you can build a client application using pretty much any programming language or framework that can speak HTTP and XML, like, say C#.
Dealing with HTTP programmatically is tedious though. Sure you can use HttpWebRequest and handle the request headers, body, status code, etc., but why do that when there’s a Twilio REST API helper NuGet package?
You can locate and install the Twilio package via the Manage NuGet Packages… context menu option on the AtHomeWebRole project, which leads to the dialog below:
or just use the Package Manager Console.
This pulls in the Twilio helper libraries (that abstract the HTTP REST calls) as well as their dependencies like Json.NET and RestSharp.
Write some code!
There are two things I want to be able to do:
- Have @home notify me via a text message that a folding unit has completed. That means I’ve accrued more points, so I may want to check my current standing amongst all the other folders.
- Allow me to send a text to @home to figure out how far along the current work unit is and get other information about how much my deployment has contributed to Stanford’s project.
Sending an SMS message via Twilio
Quite a while ago, I wrote an extensive blog series on the first version of @home with Windows Azure. The recent incarnation is a bit simpler (a single Web Role), but the general workflow is the same – essentially a thread loops continuously in the Web Role invoking Stanford’s command-line Folding@home console client. The Azure Web Role continually checks if the console client process is complete. When the process does complete successfully (meaning a work unit is done), the Web Role simply starts up another process and work unit ad infinitum.
During the polling process, the Azure role consults the percentage of completion that’s recorded in a small text file that the Stanford client updates as it is executing, and writes that value to the Azure Table storage account associated with your deployed application (UpdateLocalStatus, line 324 below) and to SQL Azure that’s part of the main @home site (UpdateServerStatus, line 325 below). If you’re looking at the source code, this all happens in the Launch method of FoldingClient.cs.
316: // when work unit completes successfully317: if (exeProcess.ExitCode == 0)318: {319: // make last update for completed role320: FoldingClientStatus status = ReadStatusFile();321:322: if (!status.HasParseError)323: {324: UpdateLocalStatus(status);325: UpdateServerStatus(status);326: }327: }328: elseIt’s the IF condition above that detects when a folding unit has completed, so we need to send the SMS right after updating the local and server status. Here’s the modified code, with the additions (and one change) highlighted.
316: // when work unit completes successfully317: if (exeProcess.ExitCode == 0)318: {319: // make last update for completed role320: FoldingClientStatus status = ReadStatusFile();321:322: if (!status.HasParseError)323: {324: WorkUnit workUnit = UpdateLocalStatus(status);325: UpdateServerStatus(status);TimeSpan duration = workUnit.CompleteTime.Value - workUnit.StartTime;String msg = String.Format("WU completed{4}{0}/{1}{4}duration: {2:#0}h {3:00}m",status.Name, status.Tag, duration.TotalHours,duration.Minutes, Environment.NewLine);TwilioRestClient client = new TwilioRestClient("ACcdd159...9a237", "fde24...d14");client.SendSmsMessage("415-000-0000", "508-000-0000", msg);326: }327: }328: elseIn Line 324, you’ll note a modification was made to UpdateLocalStatus to return information about the work unit for use later in this method. That change required modifying the return type of that method from void to WorkUnit, and returning the instance of the work unit class that was previously only used as a local variable in that method.
Most of the code added is to craft the SMS text! Sending the SMS requires only two lines of code – one to instantiate the Twilio client proxy, passing in your Twilio account SID and authentication token, and the other to send the message from the sandbox account number to the cell phone number that you explicitly verified earlier.
Here’s how it all maps out; of course, you wouldn’t hardcode values like this, and probably instead use custom service configuration settings you’d define in ServiceDefinition.csdef and ServiceConfiguration.cscfg.
Now as each Folding@home client invocation completes, I get a text message to my phone that looks something like you see to the right. The “Sent from the Twilio Sandbox Number” prefix is another ‘feature’ of the trial account; when you upgrade to a paid account, that goes away.
By the way, you don’t actually have to deploy this to Azure either. In fact, to get the various screen shots for this post, I’ve been using the Windows Azure emulator and the mock folding client we provide with @home with Windows Azure.
Receiving an SMS Message in Twilio
What we just implemented was a pushed message, triggered by the completion of a work unit. Folding@home units can take a number of hours to complete though, and what if you want to know right now how far along a job is? Now instead of the application initiating the SMS, you want the end-user to do so from his or her phone and have the @home application respond.
Sending a text is easy enough, just send it to the Sandbox number (prefaced by the Sandbox PIN for the trial accounts), but of course you need something on the other end to interpret the text and act on it. That’s where the two URLs on the Dashboard come in. Those URLS are endpoints to REST services that respond to SMS or voice messages originating from a validated sender. The default services simply display/play a welcome message, so we’ll need to do something a bit more sophisticated, something that takes the user’s SMS message as input and sends a reply SMS containing the relevant @home stats.
There are a number of different ways we could write such a service, with the new ASP.NET Web API perhaps at the top of the list. Rather that get sidetracked by yet another new and cool technology though, I’m going to keep it simple (albeit a bit kludgy) and just add a simple ASP.NET ASPX page to AtHomeWebRole (which is essentially an ASP.NET Web Forms application). The page, SMSStatus.aspx, doesn’t have any markup, just a Page_Load method:
1: protected void Page_Load(object sender, EventArgs e)2: {3: String command = Request["Body"].Trim();4: String outgoingMsg = String.Empty;5:6: switch (command)7: {8: case "current":9: outgoingMsg = "<current status goes here>";10: break;11: case "total":12: outgoingMsg = “<total contribution to date>";13: break;14: default:15: outgoingMsg = String.Format("invalid request: {0}", command);16: break;17: }18:19: Response.Write(String.Format(@"<?xml version=""1.0"" encoding=""UTF-8""?>20: <Response>21: <Sms>{0}</Sms>22: </Response>23: ", Server.HtmlEncode(outgoingMsg)));24: }This code will process two messages sent via SMS from a user. When the word “current” is texted (prefaced by the Sandbox PIN for a trial account), a response will be sent consisting of the message seen on Line 9. Likewise, when the word “total” is texted, the user will receive a reply message shown on Line 12.
Of course, these are all hardcoded strings for illustration; in my actual deployment, I’m calling a method to process each message and pulling information from Windows Azure Storage to provide the current percentage complete of a work unit, total number of folding jobs running, number complete, etc. – processing similar to what occurs to build the Status.aspx page that’s part of the same @home with Windows Azure project. Obviously, you can do whatever processing you want, just as long as you wrap up your response in TwiML as you see on Line 19ff.
The last step here is to indicate that this ASPX page should be the desired target to be executed whenever a text is sent to the Sandbox number. That association is made in the Twilio Dashboard, by specifying the location of SMSStatus.aspx as the SMS URL. Of course, at this point you can’t test this (easily) within the local Windows Azure emulator, because http://localhost won’t be resolvable, I deployed my updated @home at Windows Azure solution to http://twiliotest.cloudapp.net, and so the complete SMS URL is:
http://twiliotest.cloudapp.net/SMSStatus.aspx
Now I can start texting my application!
Wrap Up
I hope the article provided some useful insight into how easy it is to incorporate Twilio into a Windows Azure application. I didn’t touch on the voice aspects, but the process would be quite similar, and you could dial in from a landline (if you can find one) and get your @home with Windows Azure stats.
Twilio also has an offering called Twilio Connect which makes building and pricing SaaS applications that much easier. Instead of you having to provision a number and metering the billing among your clients, Twilio Connect enables your application to tap into your customers’ existing Twilio accounts via OAuth, so you don’t have to figure out how to split up your one big end-of-the-month bill across all of the clients that used your SaaS application.
Give it a shot, and if you have questions or issues getting it set up, let me know.
@home with Windows Azure is great (and meaningful) project to get started with Windows Azure – and now Twilio as well!








Avkash Chauhan (@avkashchauhan) described Request Filtering, URLScan With Windows Azure Web Role on 5/3/2012:
As you may know URLScan feature is deprecated from IIS7 and Within IIS 7, all the core features of URLScan have been incorporated into a module called Request Filtering, and a Hidden Segments feature has been added. Windows Azure instances for Web Role use IIS7.0 so there is no URLScan to use by default.
So if you are using Windows Azure and wants to use URLScan the preferred suggestion is to use “Request Filtering” instead of URLScan exactly same way you would do in any ASP.NET website running on IIS7.0+.However if you really have to use URLScan with Windows Azure Web Role your will have to install URLScan using WebPI in Startup task and then configure it as well.
Following is the batch script to install URLScan during Windows Azure Web Role Startup Task:cd "%~dp0"
md appdata
reg add "hku\.default\software\microsoft\windows\currentversion\explorer\user shell folders" /v "Local AppData" /t REG_EXPAND_SZ /d "%~dp0appdata" /f
WebPICmdLine.exe /accepteula /Products:UrlScan
reg add "hku\.default\software\microsoft\windows\currentversion\explorer\user shell folders" /v "Local AppData" /t REG_EXPAND_SZ /d %%USERPROFILE%%\AppData\Local /f
exit /b 0Thanks to Arvind MSFT for providing the script.

Kevin Remde (@KevinRemde) asserted I love these Windows Azure success stories in a 5/1/2012 post:
“MediaValet Thrives on Microsoft’s Cloud Platform” is the title of this press release. It’s great to hear about the cases where Windows Azure is being used so effectively, and really taking full advantage of its… well.. advantages. Things such as global scale and pay-as-you-go. Great, reliable, redundant storage. And the opportunity to create some massively parallel compute engines for heavy tasks such as image or video rendering.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) announced I’m Speaking Next Week on What’s New with LightSwitch in Visual Studio 11 on 5/4/2012:
I’ll be speaking next week at the East Bay.NET User Group in Berkeley as well as delivering a MSDN webcast on What’s New with LightSwitch in Visual Studio 11. I hope you can either make it in person or join in online to see and discuss the exciting new features LightSwitch will bring you. I always have a blast delivering these so I hope you can join!
What's New with LightSwitch in Visual Studio 11
Microsoft Visual Studio LightSwitch is the simplest way to build business applications and data services for the desktop and the cloud. LightSwitch contains several new features and enhanced capabilities in Visual Studio 11. In this demonstration-heavy webcast, we walk through the major new features, such as creating and consuming OData services, new controls and formatting, new features with the security system and deployment, and much more.
East Bay.NET User Group: What's New with LightSwitch in Visual Studio 11
Thursday, May 10, 2012 6:45 PM Pacific TimeMSDN Webcast: What's New with LightSwitch in Visual Studio 11
Friday, May 11, 2012 1:00 PM Pacific TimeHope to see you there!


Paul van Bladel explained Dynamically hiding columns based on modelview info rather than column header names in a 5/4/2012 post:
Introduction
It can happen that certain columns in a grid need to be hidden based on particular process logic.
You can find solutions on the LightSwitch forum where the column header name is used for retrieving the column to hide. So, that means using “magic string”.
I’m proposing here an approach that:
- firstly uses the “backing viewmodel” rather than column names. This means that the column to be hidden is identified by the name how it is known in the domain model. So, if I want to hide the City column, I specify “City” although the column header maybe something completely different.
- secondly, avoids the usage of magic strings so that we can leverage compile time checking.
Note that hiding columns should never be done solely due to security reasons. Don’t forget that even if you hide a column, the data is still going over the line.
Proposed solution
Let’s stick to an easy example. We have an editable grid screen showing customers having 2 fields: LastName and City.
Our sophisticated process logic dictates us that we should hide the City column.
Let’s first show the approach how we hide the City column based on the City field as known in the domain model. We still hardcode the value in the variable propertyToHide.
public partial class EditableCustomersGrid { partial void EditableCustomersGrid_InitializeDataWorkspace(List<IDataService> saveChangesTo) { string propertyToHide = "City"; this.FindControl("grid").ControlAvailable += new EventHandler<ControlAvailableEventArgs>((s1, e1) => { IContentItem contentItem = (e1.Control as Control).DataContext as IContentItem; foreach (var item in contentItem.ChildItems.First().ChildItems) { if (item.BindingPath == propertyToHide) { item.IsVisible = false; } } }); } }Pretty easy, no?
So, try to rename the control name into something else and you’ll see it still works
In a next step we want to get rid of the “magic string” City:
public partial class EditableCustomersGrid { partial void EditableCustomersGrid_InitializeDataWorkspace(List<IDataService> saveChangesTo) { string propertyToHide = Application.CreateDataWorkspace().ApplicationData.Customers.AddNew().Details.Properties.City.Name; //the above line could be simpler if we were able to presume that there is at least one record available in the customers screen collection //in that case we could simply retrieve the fieldName as follows: //string propertyToHide = this.Customers.First().Details.Properties.FirstName.Name this.FindControl("grid").ControlAvailable += new EventHandler<ControlAvailableEventArgs>((s1, e1) => { IContentItem contentItem = (e1.Control as Control).DataContext as IContentItem; foreach (var item in contentItem.ChildItems.First().ChildItems) { if (item.BindingPath == propertyToHide) { item.IsVisible = false; } } }); } }So, you might wonder what is the added value of this ?
string propertyToHide = Application.CreateDataWorkspace().ApplicationData.Customers.AddNew().Details.Properties.City.Name;We can illustrate this by renaming in our domain model the City column into “Town”.
Compile now and you will get following compilation error message:
I’m still in search for a better way, the the one below, to get the property name. In this version I need to do a CreateDataWorkspace, which is not optimal:
string propertyToHide = Application.CreateDataWorkspace().ApplicationData.Customers.AddNew().Details.Properties.City.Name;Conclusion
Well, sometimes you should be happy with an error message. At least we know now that we should update some code to get the column hiding working again. When using magic strings we only will get the error message when visiting the screen, or worser, when the application has been deployed.
So, with a minimal effort we can bring in some additional robustness in LightSwitch.





Return to section navigation list>
Windows Azure Infrastructure and DevOps
No significant articles today.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
The Microsoft Server and Cloud Platform Team recommended Building Cloud Infrastructure with Windows Server 2012 and System Center 2012 SP1 on 5/3/3021:
Read this great post on the Windows Server Blog by Anders Vinberg, a Technical Fellow in our Management Division. In the post he describes how the Virtual Machine Manager component in System Center 2012 SP1, now available as a community technology preview, builds on the cloud optimizing features of Windows Server 2012 to take that solution to the next level. Topics discussed:
- The cloud model and the two different cloud personas (“Service provider” and “Service Consumer”)
- How Windows Server 2012 and System Center 2012 SP1 deliver this model
- How Windows Server 2012 and the Virtual Machine Manager component in System Center 2012 SP1 provide the ability for service providers to utilize SMB 3.0 storage for VM’s and create isolated networks using Hyper-V Network Virtualization

Wonder why these folks have an out-of-focus avatar.
JP Morgenthal (@jpmorgenthal) asserted The Key to Private Cloud Is Removing IT Stratification in a 4/30/2012 post (missed when published):
One of the leading problems plaguing IT organizations is the high costs of operations and maintenance. The industry average is roughly 70% with some organizations going as high as 90%. Picking apart these costs one often finds a stratified organization focused on narrow bands of computing with little crossover between the bands. Moreover, the weighting of political density between layers often makes it too risky for basic collaboration between the stratified layers. Hence, when problems arise, each layer attempts to solve the problems only with the tools at their disposal. The result is the Operation Petticoat wired together with chewing gum and bras that we call IT.
JP’s IT Axiom #124: Design flaws at the top of the stack will highlight limitations at the bottom of the stack. Likewise, the design at the bottom of the stack impacts performance at the top of the stack.
There’s no escaping the fact that a poorly-designed application will put undue burden on the operating infrastructure. A “chatty” application impacts bandwidth. Improperly designed database queries will consume memory and disk capacity. Poorly-designed storage architecture will limit the amount of I/O per second (IOPS) and, thusly, limit the speed of retrieval of data to the application. IT transformation is about moving from a stratified organization to an agile organization through the use of DevOps culture and other collaborative techniques.
Short of correcting this organizational challenge, the stratified layers will attempt to correct issues using the tools at their disposal. Hence, infrastructure & operations (I & O) will scale linearly with memory, servers and storage to correct design flaws in the application. Software engineering will add specialized code to work around limitations in the infrastructure, such as timeouts and latency. Removal of the stratification in favor of collaborative teams means that issues can be rooted out and solved appropriately.
Moreover, this stratification has greater implications for delivery of private cloud services to the organization. Indeed, while many organizations focus on delivering Infrastructure-as-a-Service (IaaS) from their private cloud, it begs the question, “What is cloud strategy for the organization?” IaaS implies that the consumer will manage their own applications in the cloud and that IT is simply the supplier of infrastructure services. I posit that this is merely an extension of the stratification of IT with the I & O layer delivering within their swimlane. However, it misses the greater opportunity for the business a whole, which is to deliver reliability, quality, trust and scalability for data and applications in a consistent manner.
Hence, IT organizations should be focused on delivering Platform-as-a-Service (PaaS) to the business as this will provide a consistent way to design, build, deploy and manage applications resulting in lowering operational overhead while delivering greater overall agility. By delivering IaaS, the business loses the opportunity for this consistency as engineering teams are now responsible for building and deploying their own application runtime platforms. Even if a single vendor’s application platform is used, the various configurations will make it more difficult to support, lead to longer repair cycles and add undue complexity to operational concerns.
Private cloud computing represents a unique opportunity for the business to reduce operating overhead significantly through the three C’s: consolidation, consistency and congruence. To achieve this goal, IT needs to break down the stratified layers and formulate workload teams comprised of members from various parts of the IT organization and together become responsible for the workload’s availability, performance and consumer experience.

No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
 No significant articles today.
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Himanshu Singh (@himanshuks) posted Windows Azure Community News Roundup (Edition #17) on 5/4/2012:
Welcome to the latest edition of our weekly roundup of the latest community-driven news, content and conversations about cloud computing and Windows Azure. Here are the highlights from this week.
- How to Create an RSS Feed from Windows Azure Table Storage Data by @liamca (posted May 3)
- How to monitor your Windows Azure application with System Center 2012 (Part 2) by @dcaro (posted May 2)
- I’ve Built a SaaS Solution on Windows Azure; Now, How Do I Know What to Charge my Customers by @plankytronixx (posted May 1)
- Adding SMS Notifications to Your Windows Azure Projects by Luke Jefferson (posted April 30)
Upcoming Events, and User Group Meetings
North America
- May 8: Using Windows Azure Toolkit to Create Rich User Apps – (online)
- May 8: Windows Azure Kick Start – Minneapolis, MN
- May 14: Central Ohio Computer User Group – Columbus, OH
- May 17: Windows Azure Kick Start – Waukesha, WI
- May 30: Cloud Camp – Reston, VA
- May – June (multiple dates): Windows Azure Workshops – Canada (6 cities)
- June 11-14: Microsoft TechEd North America 2012 – Orlando, FL
Europe
- May 8: UK Windows Azure User Group – London, UK
- May 9: Windows Azure User Group Meeting – Manchester, UK
- May 10: Aditi London (Windows) Azure Summit – London, UK
- May 11: Windows Azure Bootcamp – London, UK
- May 15-16:CloudConf 2012 – Moscow, Russia
- May 16: Big Data using Hadoop on Windows Azure – Antwerp, Belgium
- May 18: Windows Azure Bootcamp – Liverpool, UK
- May 23-24: DevCon 12 – Moscow, Russia
- June 2: Windows Azure Saturday - Huizingen, Belgium
- June 22: Microsoft UK Cloud Day – London, UK
- June 28: Cloud East – Cambridge, UK
- June 26-29: Microsoft TechEd Europe – Amsterdam, Netherlands
Other
- May 22-24: Integration Master Class with Richard Seroter – Australia (3 cities)
- Ongoing: Cloud Computing Soup to Nuts - Online
Recent Windows Azure Forums Discussion Threads
- Mounting VHD Cloud Drive Crashes Worker Role – 544 views, 8 replies
- How to Store the Image on BLOB and the URL of the Image in MS SQL Database – 525 views, 8 replies
- BCP Inside (Windows) Azure – 606 views, 6 replies
Send us articles that you’d like us to highlight, or content of your own that you’d like to share. And let us know about any local events, groups or activities that you think we should tell the rest of the Windows Azure community about. You can use the comments section below, or talk to us on Twitter @WindowsAzure.

Michael Collier (@MichaelCollier) announced on 4/28/2012 the CloudDevelop Conference on 8/3/2012 in Columbus, OH:
I was attending the first M3 Conference last November when I started talking with a few buddies there about what we thought of M3. The attendance, sessions, and general “buzz” during M3 as people discussed, debating, learned, and compared the various mobile platforms was great! As guys with a passion for cloud computing, we were thinking that there really should be something similar to M3 but for cloud computing.
The goal with CloudDevelop is to be the Midwest’s premier conference for cloud technologies and application development. I feel it is important to point out that CloudDevelop is cloud vendor / technology neutral. CloudDevelop will feature sessions that cover all cloud platforms and services. By having a mixture of cloud computing vendors, technologies, and topics at CloudDevelop, the organizers feel that will provide a dynamic and engaging conference for all attendees.
If you would like to speak at CloudDevelop, I would encourage you to get your best Windows Azure, Amazon AWS, Heroku, AppHarbor, Google AppEngine, etc. session abstract ready and submit a few sessions today! Please submit sessions at http://clouddevelop.org/SubmitProposal.html. The call for speakers closes on May 10th.
CloudDevelop wouldn’t be possible without the generous support of sponsors. If you’re a cloud provider or tool vendor and would like to be a sponsor of CloudDevelop, please view the sponsor prospectus at http://clouddevelop.org/CloudDevelopProspectus2012.pdf to learn more about the opportunities available.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum (@DavidLinthicum) asserted “Piston Computing's integration with VMware's Cloud Foundry surprised many, but you should expect more anti-AWS efforts” in a deck for his The battle to stop Amazon Web Services starts here post of 5/4/2012 for InfoWorld’s Cloud Computing blog:
Piston Computing plans to build a bridge to EMC VMware's Cloud Foundry, meaning it will link Piston's own OpenStack-based cloud IaaS offering. What does this mean for cloud development? It's the start of many other such integration efforts, I suspect, to battle the meteoric rise of Amazon Web Services (AWS).
Cloud Foundry is a popular open source platform service, which VMware promotes as a PaaS for any infrastructure. Piston is one of many companies that rely on OpenStack. The OpenStack fraternity includes Akamai, AMD, Broadcom, Cisco Systems, CloudScaling, Dell, Hewlett-Packard, Intel, NTT, Rackspace, and Yahoo. The OpenStack movement is really a competitive pushback on AWS in the IaaS space. Both Cloud Foundry and Piston's OpenStack are available under the Apache 2 license.
If you're working on an enterprise cloud computing strategy, you should be well aware that relationships such as the Piston/VMware deal are forged for the economic benefit of both companies by making the combination more attractive than either offering on its own. That's why we'll see more and more such IaaS/PaaS partnerships or even acquisitions in the next 18 months -- especially involving other OpenStack providers.
The rationale is obvious: AWS is eating everyone's lunch, so now is the time to pile on. If AWS were not doing so well in the market, you wouldn't see many of these partnerships -- trust me.
What's an enterprise cloud guy to do? Use these partnerships to your advantage. No matter what the motivation, they open up new paths to cloud computing success, both private and public. As everyone teams up to defeat AWS, the prices should fall and the breadth of the technology stacks should increase.
Thanks for being so ominous, AWS!

Simone Brunozzi (@simon) announced Updated Microsoft SQL Server Offerings for Amazon EC2 on 5/3/2012:
As you might know, you can use official Windows AMIs (Amazon Machine Images) to launch Amazon EC2 instances with Microsoft SQL Server, inside or outside a VPC (Virtual Private Cloud).
Many customers are taking advantage of this possibility to run different types of workloads on the AWS Cloud. After listening to customer feedback (as we always like to do) and feature requests, today we're happy to announce some updates to our Microsoft SQL Server offerings. Here they are.
- Support for Additional Instance Types
You can now launch Microsoft SQL Server on m1.small (1 ECU, 1.7 GB RAM) and m1.medium (2 ECU, 3.75 GB RAM) instance types. Since we have several instance types, you might also want to take a look at the details.- Support for Microsoft SQL Server Web Edition
For customers who run web-facing workloads with Microsoft SQL Server software, we are introducing support for Microsoft SQL Server Web Edition, which brings together affordability, scalability, and manageability in a single offering. SQL Server Web will be supported across all Amazon EC2 instance types, all AWS regions, and On-Demand and Reserved Instance offerings.- Support for Microsoft SQL Server 2012
Last, but definitively not least, we now support Microsoft SQL Server 2012 on Amazon EC2.
Customers now have immediate access to Amazon published (official) AMIs for:
SQL Server 2012 Express (AMI catalog entry)
SQL Server 2012 Web Edition (AMI catalog entry)
SQL Server 2012 Standard Edition (AMI catalog entry)
You can use Microsoft's SQL Server Comparison Chart to learn more about the features available to you in each edition.
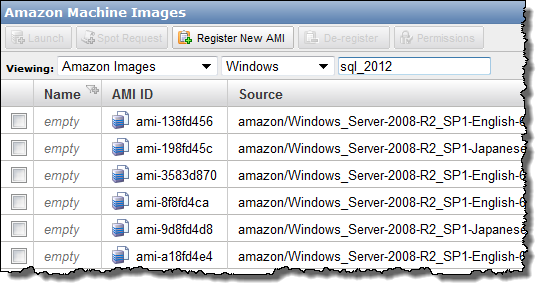
You can locate the new SQL Server 2012 AMIs by searching for the string "SQL_2012" (don't forget the underscore) in the AMI list within the AWS Management Console:
Let us know how you plan to take advantage of these new features!


Jeff Barr (@jeffbarr) reported Multi-AZ Option for Amazon RDS for Oracle Database on 5/2/2012:
The Multi-AZ (Availability Zone) feature of the Amazon Relational Database Service (RDS) replicates database updates across two Availability Zones to increase durability and availability. Amazon RDS will automatically fail over to the standby for planned maintenance and unplanned disruptions:
This feature is now available for all license types supported by Amazon RDS for Oracle Database including Standard Edition and Standard Edition One, and can be enabled with a single click, for new and existing RDS DB Instances:
In order to work properly with a Multi-AZ DB Instance, your application must be able to reconnect to the instance after a failover. We've added a new option to the rds-reboot-db-instance command to allow you to trigger a failover. You can also do this from the AWS Management Console.
When automatic failover occurs, your application can remain unaware of what's happening behind the scenes. The CNAME record for your DB instance will be altered to point to the newly promoted standby. Your client library must be able to close and reopen the connection in the event of a failover.
If you have set up an Amazon RDS DB Instance as a Multi-AZ deployment, automated backups are taken from the standby to enhance DB Instance availability (by avoiding I/O suspension on the primary). The standby also plays an important role in patching and DB Instance scaling. In order to minimize downtime during planned maintenance, patches are installed on the standby and then an automatic failover makes the standby into the new primary. Similarly, scaling to a larger DB Instance type takes place on the standby, followed by an automatic failover.
Multi-AZ deployments also offer enhanced data protection and reliability in unlikely failure modes. For example, in the unlikely event a storage volume backing a Multi-AZ DB Instance fails, you are not required to initiate a Point-in-Time restore to the LatestRestorableTime (typically five minutes prior the failure). Instead, Amazon RDS will simply detect that failure and promote the hot standby where all database updates are intact.
In addition to Multi-AZ support, Amazon RDS for Oracle Database customers can now specify any one of the thirty Oracle-recommended character sets, including Shift-JIS, when creating new database instances.
Visit the Amazon RDS for Oracle Database page for additional information about these new features.




<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, Azure Service Broker, Azure Access Services, SQL Azure Database, SQL Azure Federations, Open Data Protocol, OData, Cloud Computing, Visual Studio LightSwitch, LightSwitch, Amazon Web Services, AWS, Amazon EC2, Amazon RDS, RSS Feeds, RSS, MPNS, WNS, Windows 8, Piston Computing, Java

















0 comments:
Post a Comment