Windows Live "Fremont" vs. Google Base Classifieds
 Steve Rubel's Micro Persuasions post "Google, Microsoft to Go Hard After Classifieds" opened the Windows Live Fremont beta's kimono on November 29, 2005 by hitting the #2 position on Memeorandum. According to InfoWorld's Elizabeth Montalbano's "Microsoft to test classified service by year-end" article, Fremont will be rechristened Windows Live Classifieds when it goes into production in the first half of 2006.
Steve Rubel's Micro Persuasions post "Google, Microsoft to Go Hard After Classifieds" opened the Windows Live Fremont beta's kimono on November 29, 2005 by hitting the #2 position on Memeorandum. According to InfoWorld's Elizabeth Montalbano's "Microsoft to test classified service by year-end" article, Fremont will be rechristened Windows Live Classifieds when it goes into production in the first half of 2006.
Update: Microsoft rechristened Widows Live Classifieds as Windows Live Expo on or about 1/4/2004. A new MSN Spaces Windows Live Expo blog, which has two entries as of 1/19/2006, announced the name change.
Steve's post includes links to Greg Yardley's "Microsoft’s ‘Fremont’ a Craigslist competitor" item that includes marketing information about Fremont obtained from a Chinese MSN Places posting. Greg links to Adam Herscher, a Microsoft program manager (PM) who said, inter alia:
Unfortunately, Froogle Local isn't much help yet -- I can't find these products anywhere in Los Angeles county. I guess it's going to take some time and effort to woo over merchants. [I'm also wondering whether this is a market Windows Live Fremont intends to compete in, or if Fremont's goal is just to be a "Craigslist-killer"].
I imagine other competing services will crop up over time too. Google Base, which powers Froogle Local, provides a mechanism for merchants to do bulk imports. But in addition to allowing merchants to regularly push this information to Google Base and n other services, it'd make sense to support a standardized pull mechanism too.
Note: Adam removed the first paragraph's sentence in brackets from his current online posts, but Greg had the foresight to add a link to the cached version from which the missing sentence was extracted.
Clicking Adam's Windows Live Fremont link opens this logon page for the beta version:

Unfortunately, access to the beta version currently is limited to folks with pre-registered group e-mail addresses in the microsoft.com domain:

Products Listings vs. Classified Ads
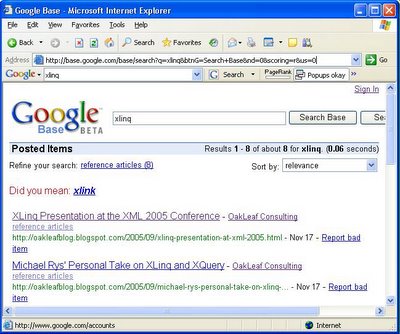
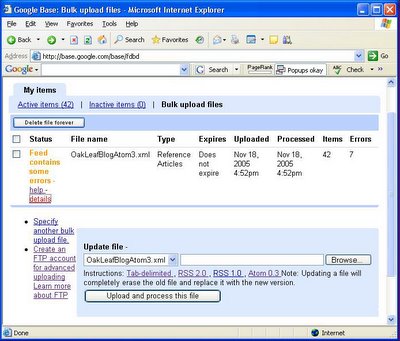
 Google got the jump on Microsoft by signing up organizations who could quickly add large numbers of entries by bulk-uploading files to Google Base.
Google got the jump on Microsoft by signing up organizations who could quickly add large numbers of entries by bulk-uploading files to Google Base.
As an example, most of the more than 13+ million Products items come from bulk uploads of ShopLocal LLC information on retail chain stores—CircuitCity, CompUSA, KMart, OfficeDepot, RadioShack, Staples, Target, and Walgreens, as of November 29, 2005. SF Mobile, Inc.'s single store appeared with 2,523 items on November 30. Products listings power the Froogle Local shopping service, which has more in common with yellow pages than newspaper-style classified advertising.
Note: The number of Products items grew by about one million (to 14,480,050) from November 29 to November 30, 2005. The number the dropped to 10,005,921 as of December 2, 2005, possibly as the result of removing spam or inactivating items that don't comply with Google Base's Program Policies.
Google relies on bulk uploads for the majority of entries for common classified item types. Online rental agents/aggregators—such as Southern California's ApartmentHunters (851 of 52,406 entries)—dominate the Rentals category. The New York Times contributes its real estate classifieds to the Housing category (10,610 of 432,575 entries). Similarly, used-car wholesalers and marketers—such as CarCast—upload bulk listings to Google Base's Vehicles category. Item types less amenable to bulk uploads have far fewer entries; for example, the entire Services item type has only 8,567 entries and Events and Activities has 3,991 items.
Note: This entry was updated on December 2, 2005. Most item counts were made on November 29, 2005.
Microsoft appears to be aiming at social networking to drive traffic, and thus entries to the Fremont database. Here's the Fremont promo text quoted from the Chinese blog:
This product represents a unique offering by Microsoft to address the person-to-person marketplace. The product, code-named “Fremont,” is a dynamic new listing service that enables people to easily buy, sell, or swap among friends, co-workers, or the public. Fremont enhances your ability to:
Note: Virtual Earth's name changes to Windows Live™ Local. (Pinging local.live.com returns 65.55.241.141; tracert times out at an msn.net router, so prepare for a move in the near future.)
* Connect with those you trust – your messenger buddies and your coworkers,
* Locate items in your neighborhood or across the country through integration with MapPoint and Windows Live™ Local (formerly Virtual
Earth),
* List easily, instantly, and for free.
Dan Farber's ZDNet "Between the Lines" blog entry of November 30, 2005, "Google Base and Fremont–signs of the Web 2.0 plateau", quotes Microsoft product unit manager Gary Wiseman, who describes Fremont as "a free listing service, with a bunch of twists to make it very unique, such as integration with social networks, in particular integration with MSN Messenger." (Microsoft promises a new Windows Live Messenger beta is "coming soon.") Farber expects Google Base to "become more of a classifieds engine." CNet's Elinor Mills adds more details from Wiseman in her November 29, 2005 "Microsoft tests classifieds service" article.
Windows Live Fremont appears to encourage manual entries by individuals—typified by Craigslist—rather than the bulk uploads that contribute the majority of Google Base entries (e.g., the 13-million Products entries). According to Wiseman, Fremont posters can limit item visibility to those in "their MSN Messenger buddy list ..., in their MSN Spaces network, or in a specific domain name e-mail group."
Dare Obasanjo's December 2, 2005 "Windows Live Fremont: A Social Marketplace" post goes deeper into Fremont's social networking aspect by likening the service to "the bulletin boards in our [college] dorm hallways."
 Obviously Microsoft doesn't want Fremont to poach users from the MSN Shopping service, which received a major facelift this year. Thus Fremont appears to be targeted as, in Adam Herscher's original words, a "Craigslist killer." It's not surprising that Microsoft has Craigslist in their sights; according to the Pew Internet & American Life Project, Craigslist is #1 in the "Top classified sites" list posted by ZDNet on November 30, 2005. Craigslist grew their unique audience 156% between September 2004 and September 2005, while second-place Trader Publishing Company grew "only" 90%.
Obviously Microsoft doesn't want Fremont to poach users from the MSN Shopping service, which received a major facelift this year. Thus Fremont appears to be targeted as, in Adam Herscher's original words, a "Craigslist killer." It's not surprising that Microsoft has Craigslist in their sights; according to the Pew Internet & American Life Project, Craigslist is #1 in the "Top classified sites" list posted by ZDNet on November 30, 2005. Craigslist grew their unique audience 156% between September 2004 and September 2005, while second-place Trader Publishing Company grew "only" 90%.
According to Search Engine Watch's "What's New in Shopping Search 2005" article for November 30, 2005:
MSN Shopping now uses product feeds from eBay, PriceGrabber and Shopping.com in addition to the feeds it has always used from major merchants. The result is more than 27 million product offers from over 7,000 stores. But MSN goes beyond simply aggregating product offerings.
MSN Shopping has a team of category managers who specialize in particular areas, such as consumer electronics and jewelry, and tailor the search/browse experience to meet the needs of consumers shopping for those types of products. The company also aggressively "cleans" data from product feeds to avoid duplicate offerings.  Shailesh Prakesh, lead product manager for MSN Shopping explained how MSN Shopping processes eBay auction content in his December 2, 2005 MSN Shopping Insider post, "eBay Selection on MSN Shopping":
Shailesh Prakesh, lead product manager for MSN Shopping explained how MSN Shopping processes eBay auction content in his December 2, 2005 MSN Shopping Insider post, "eBay Selection on MSN Shopping":
Inventory on eBay is constantly changing and in order to bring our consumers the freshest catalog of choices possible, we parse, load, classify and match the tens of millions of eBay items on a daily basis. We have invested in building out our software platform to handle such high churn workloads and have expanded our server infrastructure to efficiently and quickly ingest the inventory available on eBay, along with the catalogs of our existing merchants and aggregators. All told, we sift through hundreds of millions of items every day.
Obviously, adding "high-churn" items from product auctions requires real-time updates to the back-end database. It appears to me that latency of the current Google Base back end wouldn't support real-time processing of auction items.
Note: The MSN Shopping Insider blog has entries posted by Microsoft marketing folks, so the content is mostly PR-related. "See "Bulk-Uploaded Items Disappear from Google Base" for a description of issues with Google Base's duplicate item inactivation process.
 Thus it's certain that Fremont will have far fewer entries and, consequently, page views than Google Base or MSN Shopping. Google's combination of Froogle Local Shopping, a Craiglist clone, and other item types—Events and Activities, News and Articles, Recipes, Reference Articles, and Reviews that aren't related to ecommerce—will result in many more page views and thus greater opportunity for Google Base advertising revenue. However, BusinessWeek's Robert Hof gives Froogle thumbs down in his December 5, 2005 "Froogle: Shopping Made Complex" product review. According to Hof, "Froogle still can't match the leaders [Shopping.com, Shopzilla, and Yahoo! Shopping] in what really matters: quickly researching and finding the just the products you want." Forbes' Rachel Rosmarin is even less enthusiastic in her earlier "Google's Empty Stocking" article about three-year-old Froogle, which is still in beta. Obviously, the problems need fixing if Google wants to give Craigslist or competing retail sites a run for the money.
Thus it's certain that Fremont will have far fewer entries and, consequently, page views than Google Base or MSN Shopping. Google's combination of Froogle Local Shopping, a Craiglist clone, and other item types—Events and Activities, News and Articles, Recipes, Reference Articles, and Reviews that aren't related to ecommerce—will result in many more page views and thus greater opportunity for Google Base advertising revenue. However, BusinessWeek's Robert Hof gives Froogle thumbs down in his December 5, 2005 "Froogle: Shopping Made Complex" product review. According to Hof, "Froogle still can't match the leaders [Shopping.com, Shopzilla, and Yahoo! Shopping] in what really matters: quickly researching and finding the just the products you want." Forbes' Rachel Rosmarin is even less enthusiastic in her earlier "Google's Empty Stocking" article about three-year-old Froogle, which is still in beta. Obviously, the problems need fixing if Google wants to give Craigslist or competing retail sites a run for the money.
Greg Sterling, the Kelsey Group's local Internet marketing maven, reports from the 2005 Internactive Local Media Conference (ILM 05) that localized search now constitutes 35% to 40% of all search activity. Greg also reported on a ILM 05 demonstration by Erik Jorgensen, general manager for MSN search, of a forthcoming enhancement to the Windows Live Local service: Pictometry aerial oblique imagery, which is mapping with angled shots taken from low flying aircraft. Greg discusses offline vs. online inventory information in his "More on 'Froogle Local'" post and contends that "Google Base is ultimately about local" in his earlier "More Thoughts on Google Base" post.
 Local search and shopping clearly is today's hot topic among Web marketers and analysts. Even CNet Networks has climbed on the bandwagon with local shopping features for technology products.
Local search and shopping clearly is today's hot topic among Web marketers and analysts. Even CNet Networks has climbed on the bandwagon with local shopping features for technology products.
Channel Intelligence provides local availability data for more than 1,600 top-selling products. CNet has a group of participating consumer-electronic retailers —Best Buy, Circuit City, CompUSA, and OfficeMax—similar to that originally reported for Google Base Products listings.
Note: It's likely to be a challenge to select appropriate (related but non-competitive) ads for placement on Froogle Local pages, which are sure to be the largest consumer of Google Base's database server resources.
Open vs. Closed Databases
Craigslist has a much a more granular set of predefined classified advertising categories than Google Base, a pattern that Fremont will follow with a predetermined—probably SQL Server 2005—database schema. Mills quotes Wiseman: "We started this before anyone knew about Google Base. Having seen what Google Base is doing, I don't think they were aiming for a classifieds service. They don't have a taxonomy of listings like we do. They see it as an open database."
Note: Clay Shirky compares ad hoc, user-defined tags, such as Technorati's, with formal ontologies, typified by the original Web page subject classification system used by Yahoo!, in his widely-read "Ontology is Overrated: Categories, Links, and Tags" essay. See "Problems Uploading a Google Base Custom Item Type from a TSV File" for more information on taxonomies for use with Google Base items.
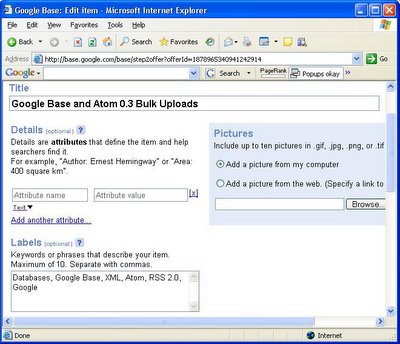
The concept of an open database where online users can define their own schema/metadata is interesting, to say the least. Google Base undoubtedly will be of more interest to developers than Fremont, especially if Google releases a Google Base API. Stay tuned for future posts on customizing Google Base Item Type categories and their attribute name/value pairs.
UIs for Open and Closed Databases
Google Base begain life as a general-purpose online database that's intended to serve as a backend to a multitude of Google—and, potentially, third-party—front ends. Thus classified advertisers and buyers aren't likely to be forced to deal with Google Base's current arcane data entry UI.
The Kelsey Group's Greg Sterling comments in his "Google Base Part III" post of November 17, 2005:
People have also been saying how Google Base is a limited or comparatively poor user experience (I made some earlier comments along these lines).
Forrester Research's Charlene Li compares Fremont's UI with that of Google Base and Craigslist in her November 30, 2005 "Why Microsoft’s classifieds service will be better than Google Base" post. Charlene is only one of two bloggers that I've encountered who've been given a Fremont preview. A better UI comparison might be Fremont and Froogle Local, which appears to be the first Google front end for Google Base. Charlene's earlier "Google Base goes live - it's more than just about classifieds" post outlines her view of the future for "Base-enabled applications."
After chatting with Google about it, I think the company is not that focused on the Google Base user experience (although there undoubtedly will be refinements). Google isn’t going to create hundreds of competitive vertical experiences around the data it collects.
Rashmi Sinha, whose background includes "Human Categorization - or how people make category judgments," offers a more thorough analysis of the Google Base UI in her "The blooming of information architecture at Google: A close look at facets, tags & categories in Google Base" post. Rashmi takes justifiable exception to Google Base's use of tags (called Names) as keywords for filtering items.
Other Trade Press and Blog Coverage: ZDnet's Garrett Rogers is late to the party with his December 1, 2005 "Google races to integrate users with services" Google blog item, as is the Associated Press with this brief "Microsoft develops classified service" article found in USA Today. ComputerWorld's IT BlogWatch for November 30, 2005, "Competition for GoogleBase," offers links to blogs reporting on Fremont, including this post. (The author, Richi Jennings, who lives in Berkshire, UK, isn't directly related to me, although he and I might have many common but distant relatives in and around Red Ruth, Cornwall. Richi recently uncovered an eBay phishing scam described in InfoWorld's December 5, 2005 "Ebay tricked by phony e-mail" article.)
Ben Charney wrote "Microsoft Testing Its Own 'Google Base'" for PC Magazine on November 29. 2005. This article version sheds no new light whatsoever on the Fremont beta. However, the "full story" on eWeek says, "Microsoft plans the first public test sometime later this month, according to a Microsoft spokeswoman." Obviously "this month" should read "next month," as there was only one day left in November.
Mary Jo Foley chimes in with a superficial "Microsoft 'Fremont': Redmond's GoogleBase Killer" piece. Seattle Post-Intelligencer reporter Todd Bishop joins the chorus with a "Microsoft tries classifieds" article. Microsoft Monitor blogger Joe Wilcox takes both Microsoft and Google to task for using betas as "soft launches" for new or upgraded applications in "Even More Beta Blues."
--rj
Technorati: Databases Fremont Windows Live Classifieds Froogle Froogle Local Windows Live Local Google Google Base MSN Shopping eBay











 Microsoft has had a long-term relationship with ECMA, having participated in the
Microsoft has had a long-term relationship with ECMA, having participated in the